
Memphis: Low-code real-time data processing platform
Message Broker fully optimized in less than 3 minutes


In this blog, I am sharing the learning that is gained from the session Batch Vs Stream Processing - How to Reduce Complexity?.
This session is really useful for those who want to learn about the advantages and disadvantages of batch vs stream processing and the open-source platform Memphis. It was a great opportunity to participate in the Batch Vs Stream Processing - How to Reduce Complexity? Session hosted by Kunal Kushwaha.
Speaker of the session: Sveta Gimpelson, Co-Founder | VP Data and research in Memphis{dev}

During the session, I learned the below-mentioned topics.
- What Memphis does ?.
- What is Stream Processing? How does it work?
- Difference between Stream and Batch Processing
- Use cases
- What is a message broker?
- Rules and regulations of data streaming
What is Stream Processing? How does it work?
- Stream processing is a big data technology.
- It is used to query a continuous stream of data and quickly detect conditions within a short period of time from when data is received.
- The acquisition time varies from a few milliseconds to a few minutes.
Difference between Stream and Batch Processing
Batch processing refers to the processing of large amounts of data in batches within a specified period of time. Process large amounts of data at the same time. Batch processing is used when the data size is known and finite. Data processing takes a little longer. It requires dedicated employees to solve problems. The batch processor processes the data in multiple passes.
When data is collected over time and similar data is grouped, then batch processing is used.
Stream processing refers to processing a continuous stream of data immediately as it is being produced. Analyze streaming data in real-time. Stream processing is used when the data size is unknown, infinite, and continuous. Data processing takes seconds or milliseconds.
In stream processing, the data output rate is as fast as the data input rate. The stream processor processes the data in a few passes. If the data stream is continuous and requires an immediate response, stream processing is used in this case.
What is a message broker?
A message broker is an architectural pattern for message validation, transformation and routing. It mediates communication between applications, minimizes the mutual awareness that applications should have of each other in order to exchange messages, and effectively implements decoupling.
A message broker is a temporary data store. Because every data in it will be deleted after a certain amount of time defined by the user. Therefore, data items in the message broker are called messages. Each message usually weighs from a few bytes to a few megabytes.
Well-known message brokers/queues are
- Apache Kafka
- RabbitMQ
- Apache Pulsar
- Memphis.dev
Let's see the overview of Memphis
Overview of Memphis
What is Memphis{dev}?
Memphis{dev} is the only low-code real-time data processing platform that provides a complete ecosystem for in-app streaming use cases using the Memphis distributed message broker with a production paradigm- consumption that supports modern, asynchronous in-app streaming pipelines communication by removing management, cost, resource, language and time frictions for data-centric developers and data engineers unlike other brokers messages and queues that require a large amount of code, optimizations, adjustments and above all time.
memphis.dev started out as a fork of the nats.io project (since 2011), written in GoLang, and building its feed on top of it.
Instead of topics and queues, Memphis uses stations, which in the future will become an entity with built-in logic.
Four Pillars of Memphis
Memphis focuses on four pillars
- Performance
Improved cache usage
- Resilience
Never lose a message and 99.99995% uptime
- Observability
Out-of-the-box observability that makes sense and reduces troubleshooting time
- Developer experience
Modularity, inline processing, schema management, GitOps capability
Where Memphis can be used for?.
- Data Logging
Record streams of data at high speed
- Live Pipeline
Move data bits between pipeline stages
- Offline Web App
Use Memphis to save offline user actions
- Task management
Use Memphis to create an asynchronous task queue
- Queuing
Memphis is great for queuing
- Communication with microservices
Keep your data as it flows between microservices
Why Memphis?
- Implementation with 1 command
It works natively on all Kubernetes and Docker environments and is fully optimized from the start.
- Zero operations
A messaging broker with great DevEx and a user interface for data engineers and developers with real-time troubleshooting and input data tracking.
- Resilient
Resilience is one of the most important building blocks of Memphis. Out-of-the-box dead-letter queue, resource optimizations, and event recovery without code changes.
- Schema management
Single, robust, and user-friendly schema management. It includes the development, transformation, validation, and application of live schemas for data contracts.
- Connectors
A hub of out-of-the-box connectors written by the community and popular apps like S3, Snowflake, Firebolt, BigQuery, and more
- Stream processing
Enrich and analyze streaming data as it arrives with serverless capabilities
Memphis Architecture
Connectivity diagram
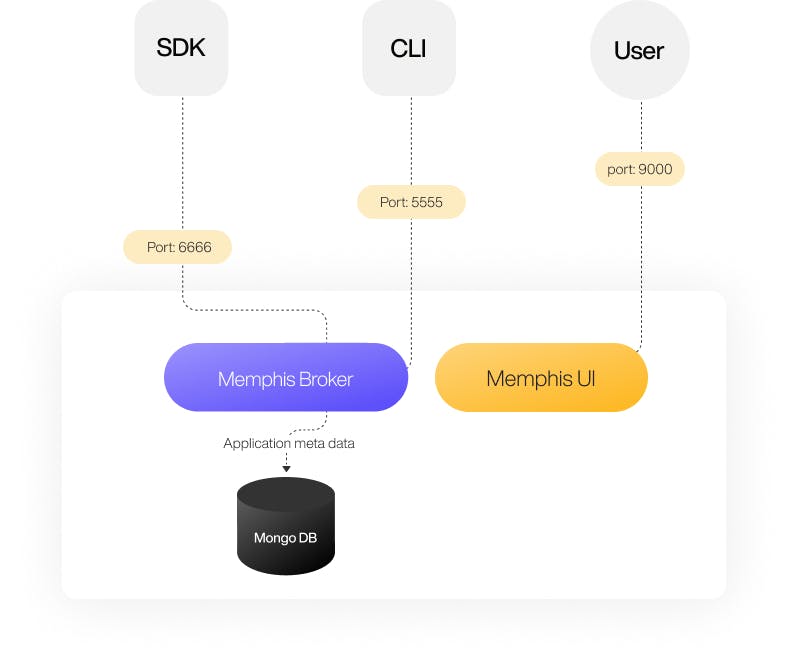
The Memphis implementation consisted of four components:
UI - The Memphis dashboard.
Broker - Message queue
The Memphis broker is a fork of, an existing and proven message queue with improvements and optimizations from Memphis.
- DB
Application state persistence (not used to store messages).
Consumers are based on the pull. Pull interval and batch size can be configured. Each consumer will receive all messages residing within a Station. If an app requires horizontal scaling and messages need to be split across different scaling group members, the user must create consumers with the same consumer group.
To order
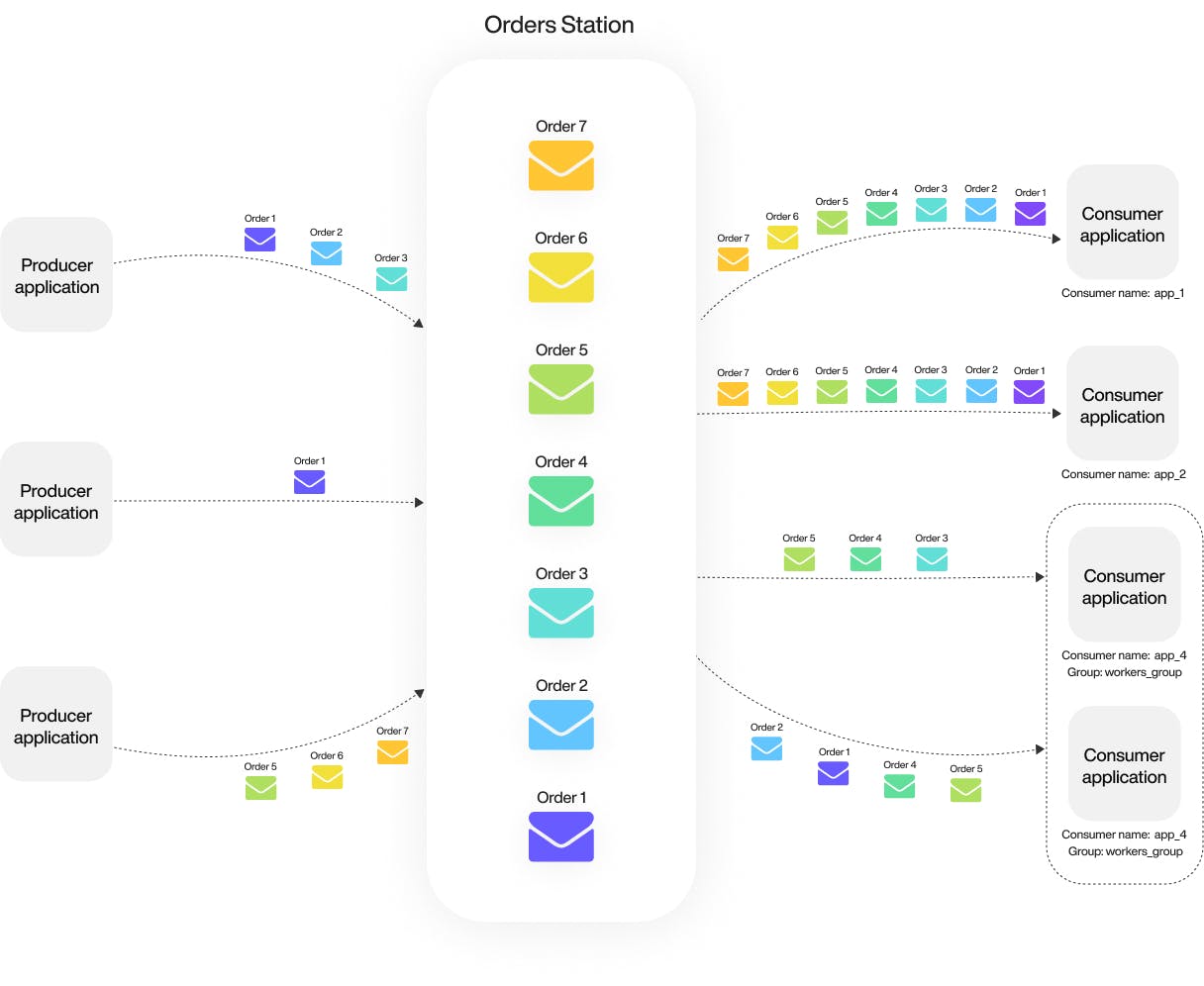
The order is only guaranteed if you work with a consumer.
Protection
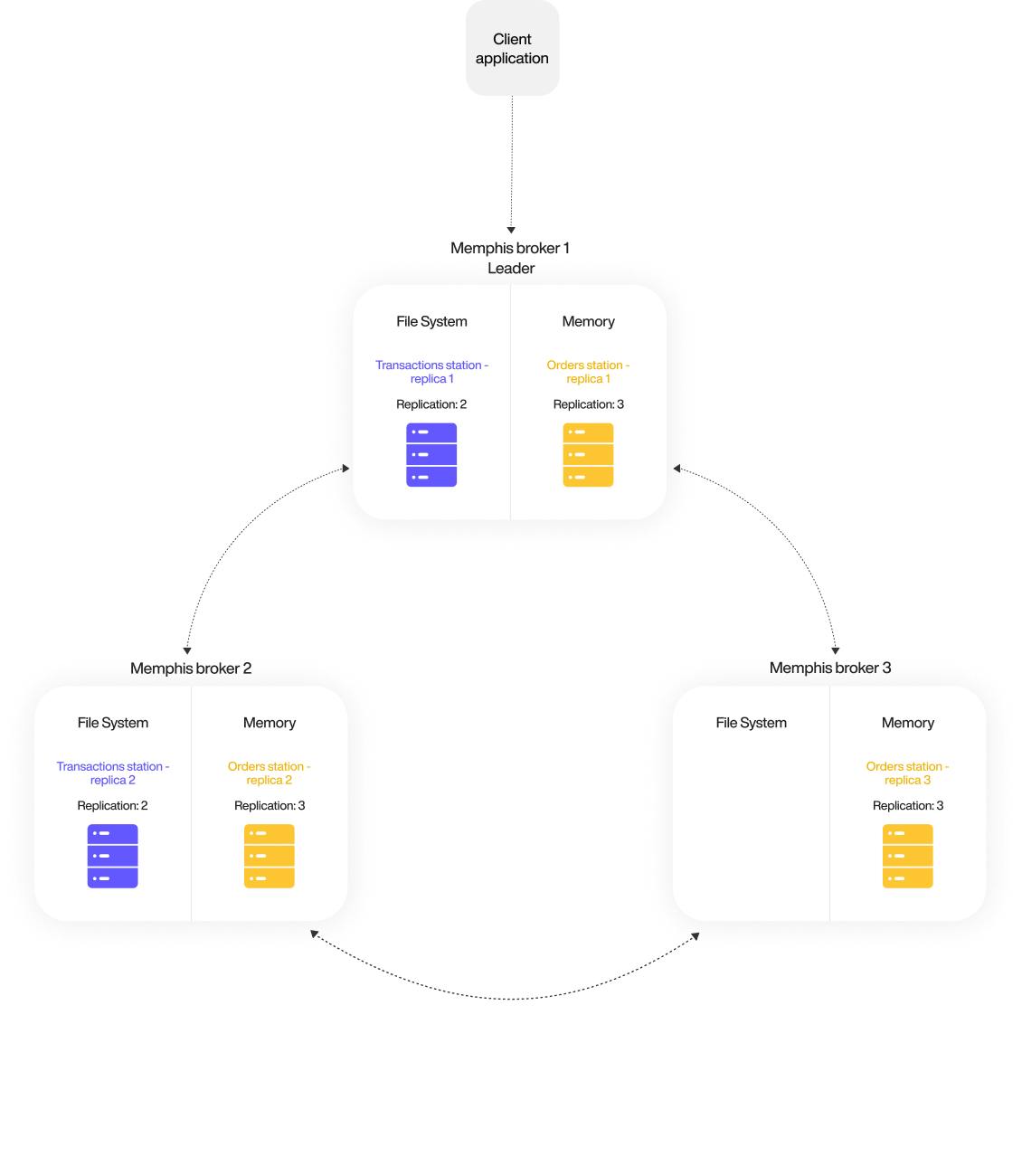
- Memphis is designed to function as a distributed cluster for a scalable and highly available system.
- The consensus algorithm responsible for atomicity within Memphis, called RAFT, and compared to Apache ZooKeeper widely used by other projects such as Kafka, does not require a Witness or a standalone Quorum.
Protocol
- Memphis branched off and changed the NATS as the main queue.
- The NATS streaming protocol sits above the main NATS protocol and uses Google's protocol buffers. Protocol buffer messages are gathered into bytes and posted as Memphis messages on the specific station.
Deploying Memphis on AWS using Terraform
Amazon Web Services, one of the three most popular cloud providers in the world, provides reliable and scalable cloud computing services. You only pay for what you use.
Currently, Memphis uses Terraform to automate the entire deployment process, from VPC creation to K8S and Memphis deployment. Terraform encodes cloud APIs into declarative configuration files.
Prerequisites
- AWS Account
- AWS CLI installed and configured.
- Make sure your local is connected to the AWS account using an AWS IAM user who has access to resource creation (EKS, VPC, EC2).
How to configure AWS CLI -
# aws configure
AWS Access Key ID [****************LQME]:
AWS Secret Access Key [****************i8x4]:
Default region name [us-east-1]:
Default output format [json]:
-Terraform is installed.
- Kubectl is installed.
- helm is installed.
Terraform installation workflow
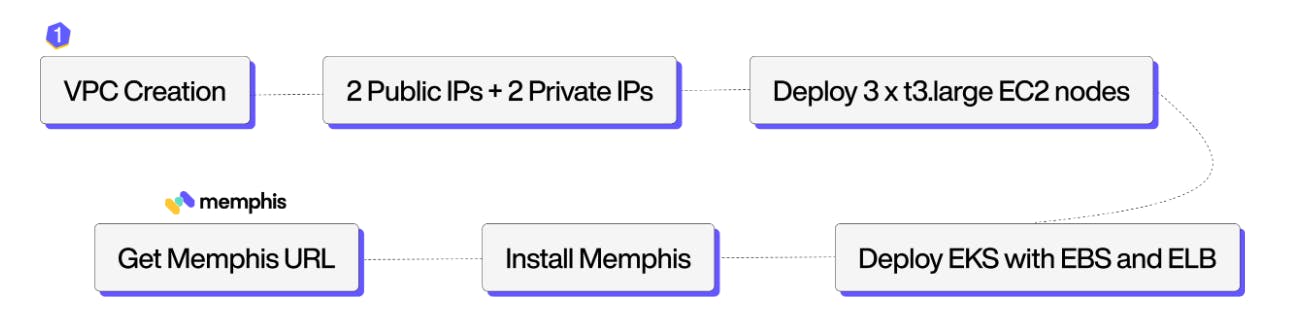
Cloud Deployment
Kindly watch the below video to deploy Memphis on AWS using Terraform
Reference Article
- Getting Started
- Sandbox Memphis
- Memphis
- memphis-broker
- Batch Vs Stream Processing - How to Reduce Complexity?
Gratitude for perusing my article till the end. I hope you realized something unique today. If you enjoyed this article then please share it with your buddies and if you have suggestions or thoughts to share with me then please write in the comment box.